PAC-файл (Proxy Auto-Configuration) АнтиЗапрета не обновляется с 28 января, из-за слишком большого количества заблокированных доменов в Реестре запрещённых сайтов, которые не укладываются в лимит браузеров на основе Chrome.
Эта проблема не нова, но до недавнего времени с ней удавалось справляться фильтром нерабочих (и припаркованных) доменов, исключением мусорных зеркал вручную, простыми алгоритмами сжатия и оптимизации. Сейчас же доменов стало так много, что у меня не получается справится в этим эффективно и автоматизированно.
Поэтому принимаются любые предложения, идеи, реализации в виде кода, которые помогут уменьшить размер файла.
Задача заключается в реализации алгоритма сжатия (упаковки) доменов и IP-адресов, который бы уменьшил размер файла до приемлемого (<950 КиБ), а также алгоритмов исключения нерабочих, разделегированных и припаркованных доменов из списка, «мусорных» зеркал сайтов.
Сейчас реализовано:
- Исключение нерабочих доменов, которые возвращают NXDOMAIN/YXDOMAIN
- Исключение припаркованных доменов, если у них указан один из известных парковочных NS-серверов
- Сжатие доменов алгоритмом а-ля RLE, который не требует разжатия (запрашиваемый домен наоборот сжимается)
- Уплощение доменов до зоны (избавление от поддоменов, кроме определённых исключений)
- Не особо эффективный разностный алгоритм для паковки заблокированных IP-адресов
Что нужно учитывать:
- PAC это Javascript, но с особым API/Runtime. В нём нельзя выполнять HTTP-запросы (вроде fetch/XMLHttpRequest), но можно резолвить DNS. В нём нет доступа до DOM/document, нет HTML.
- Нет поддержки Unicode, содержимое парсится как однобитовая кодировка cp1252. Русскоязычные домены должны паковаться в punycode, бинарные данные — в base64/base85 сотоварищи.
- Скрипт исполняется целиком при инициализации контекста JS (на каждый поток/процесс), в это время можно однократно выполнить какую-то затратную по CPU/RAM операцию. Затем на каждый сетевой запрос вызывается функция FindProxyForURL, которая возвращает результат необходимости проксирования.
- Файл должен работать в очень старых браузерах, вроде Internet Explorer 9/10/11. Если установить ссылку на PAC-файл в старой версии Windows, все программы, использующие функции wininet для общения по сети, будут исполнять файл в системной версии IE. Если в файле используются слишком новые технологии, старые клиенты в случае ошибки начнут бесконтрольно запрашивать файл по сто раз в секунду.
- В браузерах есть (неустановленное и разное) ограничение на количество потребляемой оперативной памяти PAC-файлом, поэтому алгоритмы инициализации и сжатия должны укладываться во вменяемые размеры heap. Самый ограниченный в этом плане — Firefox 52 на Windows XP 32 bit, с лимитом в 4 МБ.
- Сжатие в идеале не должно требовать инициализации при запуске: лучше сжимать/преобразовывать запрашиваемый домен при каждом запросе, а не разжимать списки блокировок в память.
Более-менее детальную информацию о структуре и функциях PAC-файла можно найти на сайте http://findproxyforurl.com/, дополнительная информация:
- GitHub - anticensority/about-pac-scripts: What we know about PAC scripts
- about-pac-scripts/pac-script-api-chrome-55.md at master · anticensority/about-pac-scripts · GitHub
Исходный код генератора: Bitbucket (branch fixmeplz)
Скачивание листов и резолвинг отключён, запускайте doall.sh и проверяйте размер result/proxy-host-ssl.pac.
Если хотите тестировать nxdomain-резолвер, запускайте только его: scripts/resolve-dns-nxdomain.py result/hostlist_zones.txt
Ой только не питухон
Пора уже отказаться о поддержки старого софта, раз это уже реально мешает развитию – XP, IE и всё такое.
Присылайте на клиент вместо полного списка простой bloom-фильтр - он супер дешевый. O(1) по процессору и O(1) по памяти. Минус - это вероятностный алгоритм, и есть шанс ложноположительных срабатываний (ложноотрицательных быть не может). Вероятность коллизий будет зависеть от числа записей и размера таблицы.
Я не знаю, сколько записей сейчас в списках РКН, но допустим 1 миллион. Тогда скажем при таблице размером 10 мегабайт вероятность ложного срабатывания будет 1 из 7 миллионов. То есть вам придется какие-то редкие незаблокированные домены через себя проксировать.
В интернете полно калькуляторов, чтобы рассчитать вероятности коллизий - Bloom filter calculator. Заведите туда ваши реальные параметры (сколько доменов в списке и сколько памяти готовы пожертвовать), и получите вероятность коллизии.
Если случайно попадется какой-то дорогой домен (ну не дай бог Ютуб будет ложноположительным), вы можете рядом с блум-фильтром ещё и черный список положить доменов, которые ни при каких условиях нельзя проксировать. И будете туда добавлять домены, если вдруг от какой-то коллизии больно будет. Но скорее всего вам никогда в жизни не придется туда ничего класть.
От этого можно избавиться, установив проверку user-agent на сервере.
Выдавать что-то вроде 404. Посмотреть какая реакция будет на разные кода.
От дятлов может спасти iptables/nftables limit /sec
Против гигантских дятлов что-то на подобии fail2ban
Вопрос как её впилить в плейнтекст-файл. Текущий размер pac-файла в районе мегабайта
@ValdikSS, сколько у тебя остаётся адресов после выкидывания ненужных? Для оценки того, сколько необходимо в таблицу Блума засунуть.
Ну это уже чисто технический вопрос. От кодировок типа base64 до встраивания png-файла и чтения попиксельно.
есть странный вопрос, а пробовали упаковать в формате privoxy ? что-то кажется, что PAC файлы это немного тупиковое
PAC-и я покопаю. может что придумается
Но при этом все еще надо как-то влезть в мегабайт. Base64 дает примерно +30% к размеру, вариант с png не звучит как реализуемый в принципе в рамках pac.
@p13dz, @goodrussian666 PAC-скрипт – это скрипт, написанный на JS, но с особым API/Runtime. В нём нельзя делать HTTP-запросы, по типу fetch, только DNS. В нём нет DOM/document и никакого HTML. Подробнее см. GitHub - anticensority/about-pac-scripts: What we know about PAC scripts и about-pac-scripts/pac-script-api-chrome-55.md at master · anticensority/about-pac-scripts · GitHub.
да, я в курсе, я имел в виду privoxy вместо pac
Некий вариант префиксного дерева?
Более эффективное использование всего диапазона значений символов, а не только разрешенных в DNS ?
Это не вариант, т.к. сломает часть сайтов. Чтобы проксировать случайные ложноположительные срабатывания, придётся на прокси-серверах разрешать всё.
Записей 1.7 млн, ограничение файла — 1 048 576 байт.
$ wc -l hostlist_zones.txt
127293 hostlist_zones.txt
Но это с исключёнными доменами, начинающимися на цифру, и другими хаками.
А ограничение на 4 Mb в браузерах на основе chrome возможно обойти? Сделать больше по размеру или разделить их по частям.Выбирать ту часть которая необходимо в данное время для прокси
Как вы это представляете реализовывать технически?
Не только на питоне это делается ProxyAutoConfig.cpp - mozsearch
Я вижу несколько вариантов:
- разбить скрипт на несколько скриптов: отдельный скрипт для .ru зоны, отдельный для .com, отдельный для .org и т.д. Подгружать динамически в зависимости от запрашиваемого домена
- хранить в файле хеши в бинарном виде
- хранить в файле бинарный бор:
Если в списке домены “aaa”, “aab”, “aba”, “caa” то нужно хранить структуру вида
{“a”: {“a”: {“a”: true, “b”: true}, “b”: {“a”: true} }, “c”: {“a”: {“a”: true} } } - сжать список алгоритмом хаффмана (вариация бора когда преждевременно анализируем потенциально самые частоиспользуемые ребра)
Плюсы подхода 3 и 4 это то что мы явно не храним весь список и нам не нужно его полностью восстанавливать для проверки на вхождение. При этом не возможны коллизии.
Немного оффтоп. Но с чем связаны такие строгие ограничения на IE7 и Windows XP?
Казалось бы сами заблокирвоанные сайты не очень умеют с ним работать.
Для таких старых устройств есть смысл делать обход блокировки средствами роутера или гейтвея или через операционную систему, не через браузер
Такой возможности нет, PAC-файлы не могут загружать сторонние ресурсы.
Только ASCII 7-бит, не все браузеры поддерживают не-однобитные кодировки.
Сервисом до сих пор пользуются со старых компьютеров, не хотелось бы ломать доступ без сильной на то необходимости.
Но даже если ориентироваться на Windows 7 и его версию IE, там тоже не получится использовать современные технологии.
Я не знаю насколько моё мнение важно, но
Мне кажется что если выбирать между
- поддерживать для 99% пользователей (а есть ли статистика?) браузер которых выпущен в последние 2 года
- не поддерживать из-за 1% пользователей которые пользуются морально устаревшими технологиями
всегда нужно выбирать первое
В текущем виде выглядит расточительно, нужно придумывать алгоритм паковки данных.
Я думал для сжатия IP-адресов реализовать Elias gamma coding.
Пользователи, добавляющие PAC-файл в ОС, начинают использовать его в браузере ОС (старые версии IE и wininet, основанный на нём).
Как насчёт взять GitHub - LZMA-JS/LZMA-JS: A JavaScript implementation of the Lempel-Ziv-Markov (LZMA) chain compression algorithm (декомпрессор весит 6.8 КБ) и зипануть все домены?
кстати, а если выделить в общую кучу Cloudflare, по идее его может быть довольно много (из-за казино), и заменить общим правилом “если адрес ресолвится в клаудфлер, то проксировать”
Нельзя ли на сервере проверять домены по тому же фильтру?
Здесь уместен вопрос. Дергается ли прокси пак каждый раз при обращении к URL или есть какое-то кэширование результатов ? Может в разных броузерах по разному ?
Если на каждое обращение, то будет тяжеловато, особенно на старых компах.
lzma 1 мб в нативном варианте разжимается около 50 мсек даже на 12700K
JS - сразу в несколько раз минуc. Если вызов идет при каждом дергании URL, на селероне 15 летней давности будете ждать секунды, если не 10+ секунд, а ноут будет выть
Сюда же в копилку гораздо более слабая оптимизация JS на старых броузерах типа iE
Потому есть предложение дифференцировать размер proxy.pac в зависимости от user-agent. Если броузер не налагает жестких ограничений, использовать лайтовую версию
Скрипт исполняется целиком при инициализации контекста js (на каждый поток/процесс, полагаю), в это время можно однократно выполнить какую-то затратную по CPU/RAM операцию. Затем на каждый запрос вызывается функция, которая возвращает результат необходимости проксирования.
По мере прочтения темы, появилось несколько мыслей:
-
Если проблема ограничения размера pac-файла в 1 MB касается только браузеров на основе Chrome, можно ли автоматически собирать отдельную неурезанную версию pac-файла для свежих Firefox, где таких ограничений нет?
-
Не совсем понятно, зачем привязываться к ограничениям в Windows 7 и её версии IE, если сам IE не способен нормально отобразить современные сайты?
Изобретать способ уменьшения размера pac-файла для браузера, который не может отобразить большую часть разблокированных сайтов, выглядит нелогичной тратой людских ресурсов, которые могли бы быть использованы в других вопросах касательно обхода блокировок.
Там еще вроде бы есть ограничения на RAM. Разжать и все хранить в виде JS переменных может быть тоже проблемно
Я ранее предлагал эту идею насчет дифференциации размера в зависимости user-agent.Но думаю не взлетит из-за излишней нагрузки на сервер.Здесь важно понимание того до какого верхнего предела по кол-ву записей можно достигнуть.Если их сейчас 1,7, то на следующий год может оказаться в три раза выше.Рост в геометрической прогрессии( хуже в экспоненциальной)
Нагрузка ложится на прокси, и она не особо зависит от размера proxy.pac
Она зависит от количества значимых доменов. Всякий мусор типа проституток новосибирска практически никому не интересен, а он как раз и составляет основу.
Сам веб сервер, выдающий прокси пак, вообще минимален по нагрузке. Статическая выдача или простейший скрипт - разницы почти нет
У меня есть вариант, который конкретно домены жмет лучше, чем текущий. Получается около 870 KиБ данных в самом proxy.pac (считая код, нужный для распаковки). Я не пробовал включить в него IP-адреса, и не проверял, сколько он потребляет памяти; буду благодарен, если кто-то с этим поможет.
Сам код сжатия работает в Node.js (почти любой версии). Он ожидает в файле src.txt в текущей директории список доменов, и выдает готовый out.pac.
Алгоритм основан на трех идеях:
- хосты для матчинга переворачиваются, т.е. с последнего по первый символ
- на перевернутых хостах строится, фактически, бор, но упаковывается в RegExp
- сам RegExp затем сжимается заменой диграмм, примерно так, как сжимаются хосты в текущем репо
compress.js (2.2 KB)
Если в качестве входных данных беру result/hostlist_zones.txt из репо, то out.pac имеет размер 875 КиБ. Прикрепляю также его, чтобы легче было тестировать потребление памяти - буду рад, если кто-то с этим поможет. На саму правильность матчинга я тестировал, но в Node.js (т.е. без учета ограничений PAC-файлов).
out.pac (874.2 KB)
Подход интересный, но regexp — точно не самое быстрое решение.
Там основная стоимость на компиляцию при первом запуске скрипта. Потом, когда функция вызывается - она дешёвая; линейная относительно длины host, если прямо заморачиваться асимптотикой.
Не знаю, насколько это приемлемо, плюс не измерял по абсолютным цифрам.
Учитывая, что сам регексп получается без бектрекинга - можно накидать простой алгоритм, который будет матчить его без именно использования RegExp. Попробую в ближайшие дни сделать.
Идея на подумать:
Произвольно руками посмотрел на cloudfront в списке, его есть смысл пытаться резолвить и выкидывать строки не резолвящиеся в какой-либо IP. Одного этого уже может быть достаточно на какое-то время
А есть какой-то сакральный смысл в том, чтобы использовать исключительно один только PAC-файл? Если добавить в инструкцию для пользователей, кроме пункта “укажите в настройках URL PAC-файла” второй пункт “а в другом месте настроек укажите адрес нашего DoH-сервера” - дальше можно реализовать ту же самую подмену IP, как и в VPN-версии, а весь PAC-файл при этом сведётся к нескольким строчкам кода, проверяющим попадание отресолвленного IP для домена в наш подменный диапазон.
Во-первых, спасибо за всё, что вы делаете!
Регулярно пользуюсь вашими сервисами.
Исходя из требований и объёма данных, предлагаю перейти на сравнение хэшей.
Каждый домен хэшируется каким-нибудь алгоритмом, например, SHA1.
(Мы не занимаемся проверкой целостности и криптографией, поэтому не имеет смысла брать более мощные алгоритмы. Можно вообще взять MD5 и даже CRC32, хоть он и предназначен для другого.)
Потом берём домен пользователя, хэшируем и сравниваем полученный хэш с таблицей хэшей исходных доменов.
Такой подход используется во многих продуктах, например, Safe Search для AdGuard.
Целые хэши занимают много места, поэтому будем брать их часть - 32 бита.
FIPS.180-4 предлагает брать префикс хэша, то есть просто обрезать остаток строки, получаем 4 байта на домен. Я провел тест на исходных 128к доменах, все 4-байтовые значения получились уникальные. Думаю, вполне хватит 4 байта.
Теперь по хранению всего этого безобразия.
Для ускорения поиска нужно разбить данные на части.
От хэша домена возьмём старший байт, который будет использоваться для индекса.
(Индекс лучше хранить в десятичном виде, занимает меньше места.)
Оставшиеся 3 байта можно закодировать алгоритмом BASE64, который для 3 байт выдаст строку 4 байта.
В эту строку добавим граничный символ “#”, чтобы было проще искать.
В результате получается следующая структура:
domains = {
...
123:"#ABCD#EFGH#...",
124:"#IJKL#MNOP#...",
...
};
Оценка размера структуры.
У нас получается 5 байт на домен и накладные 256 по 8 байт (3 на индекс, 2 на кавычки, 1 на двоеточие, 1 на запятую, 1 на новую строку).
Итого 128000 * 5 + 256 * 8 = 642048 байт.
Алгоритм поиска.
На входе домен пользователя host, считаем от него хэш SHA1(host), берём старшие 4 байта WXYZ.
Байты XYZ кодируем: host64 = BASE64(XYZ).
Добавляем в host64 граничный символ: host64 = “#” + host64.
Если domains[W] существует, тогда в строке domains[W] ищем подстроку host64 с помощью indexOf().
Если значение не равно -1, то хэш найден, домен пользователя в списке.
Оценка реализации.
Получается, что браузеру пользователя нужно посчитать хэш SHA1 для домена, BASE64 для 3 байт хэша и выполнить поиск подстроки в строке.
Это лучше, чем использовать регулярные выражения и алгоритмы сжатия для всей таблицы.
Если предположить, что 128к доменов распределены равномерно по таблице, тогда размер строки равен 128000 * 5 / 256 = 2500 байт.
Пусть даже строка будет в 10 раз длиннее, всё равно поиск будет выполняться достаточно быстро.
Реализация SHA1 занимает около 3 КБ, где-то видел варианты поменьше.
BASE64 в современных браузерах реализован в виде функций atob()/btoa(), для старых можно реализовать отдельно (1, 2).
Думаю, с учётом размера структуры и реализации этих алгоритмов получится вписаться в 700 КБ.
Возможные проблемы.
Из-за коллизии может получиться так, что 32 бита хэша легитимного домена совпадут с таблицей.
На этот случай можно предусмотреть список исключений. Не думаю, что он будет большой.
Реализации SHA1/BASE64 надо тщательно проверять под все версии браузеров, особенно старых.
Оптимизация 1.
Можно отказаться от граничного символа и хранить все хэши подряд “ABCDEFGH…”, это уменьшит размер структуры до 500 КБ.
Но тогда придётся искать все совпадения подстроки и смотреть, чтобы подстрока приходилась на начало блока. Если индекс совпадает с началом блока (index % 4 == 0), тогда хэш найден, иначе искать дальше вплоть до конца строки.
Размер уменьшается, но скорость обработки увеличивается.
Оптимизация 2.
Вариант оптимизации 1 можно улучшить сортировкой хэшей и использованием бинарного поиска.
Думаю, пока можно обойтись без оптимизаций, этого хватит на какое-то время.
Надо бы сделать прототип, но я давно не писал на JS, быстро не получится.
Вот насчёт этого сомневаюсь, кстати. Заблокированных доменов очень намного меньше, чем незаблокированных, поэтому не уверен, что решение с false positives тут подойдёт.
Кроме того, этот список исключений нереалистично будет обновлять автоматически. Для заблокированных есть источники, а исключения собирать как? Проверять хэши вообще всех доменов в интернете?
а исключения собирать как?
Видимо, автоматически никак, только по жалобам пользователей.
Если 32 бита хэша кажется мало, можно взять 40 бит.
Тогда придётся заменить BASE64 на ASCII85, который 4 байта кодирует в 5 байт.
В этом случае размер таблицы данных будет 128000 * 6 + 256 * 8 = 770048 байт.
А что, если исключать сайты и адреса, которые действительно являются scam, spam, срам… Которые в базах, например, virustotal содержатся.
Идея мало практичная, но тем не менее, если можно резолвить dns, можно складывать данные в поддомен, получать обратно 32 бита в виде айпишки с собственного ns сервера. Без понятия какие данные так гонять (сами адреса стрёмно, может хеши или что-то такое? по 32 хеша?), оно будет оседать в кешах dns, что и хорошо и плохо.
Плохо, что у большенства юзеров dns открытым текстом
Сейчас в списке примерно так и сделано: домены группируются по длине и добавляются в строку без разделителей, а затем разделяются (также по известной длине) в массив строк. Это требует инициализации, но не затратной.
Идея а-ля DNSBL рабочая, но лучше к ней не прибегать: это заметно повысит latency запросов, добавит еще одну точку отказа, да и браузеры иногда с DNS в PAC-файле плохо работают.
Проще уж тогда на VPN-серверах каждый день собирать статистику по доменам и генерировать PAC-лист только из тех, к которым регулярно обращаются. Что тоже дерьмовый вариант.
Кстати, а что на счет расширения броузера ?
Расширение имеет куда большие полномочия и не имеет столь жестких ограничений
Да, недоступно для мобильников, но там и так в основном пользуют VPN
Вот тут нагуглилось “supports inline PAC script”
Значит он его в себя подгружает, и там уже нет ограничений
В расширениях такого ограничения нет. PAC-файлы и так используются в «Обходе блокировок Рунета» и CensorTracker.
Тогда чего мы мучаемся. Возможности PAC исчерпаны. Загоняем всех на расширение и дело с концом.
Расширения есть на всех современных броузерах для PC, а ослика давно пора отправить на покой
Кстати, в условиях отсутствия публичного списка заблокированных сайтов, как планируется обновлять список доменов ? Основные значимые - руками вносить ?
PAC-файл работает не только в браузерах.
У меня есть пара идей по автоматическому обнаружению блокировок, напишу позже.
Но ведь ограничение на 1 мб только хромовское ? В других местах пусть будет большой pac
смотрите какая красота. в list.csv примерно 500 тыс записей
если сделать вот так
cat list.csv | awk 'BEGIN{FS=";"} NR >1 {print $1}' | sort | uniq -c | sort -rn | more
в топе значительная доля клаудфлера
Electron’овское ещё.
Как предлагаете использовать этот факт?
схлопнуть клаудфлеровские адреса в ноль и через isInNet() маршрутизировать их на прокси
Не анализируя домен? Проксироваться будет пол интернета в таком случае.
А IP-адреса в PAC-файле и так небольшую часть занимают, меньше 20 КБ.
awk: cmd. line:1: warning: regexp escape sequence _’ is not a known regexp operator`
а как это фиксить?
Так и должно быть, это не ошибка.
Я попробовал другую библиотеку но с тем же алгоритмом. Изначальный файл 2.2 мб, выходит 1.3 мб после сжатия. Попробовал сжать уже сжатое и выходит теже 1.3 при том что сжатый файл 1.1 мб.
Пока есть идея сжать просто по модулю. Всего 39 символов то есть в 128 бит ASCII можно вместить 3 символа в одном. И сейчас те 2 мегабайта как 700 килобайт представить + алгоритм разжатия довольно простой. Тьфу в 128 возможных чисел. Взять по модулю. И будет сжатие в 3 раза по сути. Нужно конечно проскипать символы закрывающих кавычек, экранироваия и перевода строки.
Реализовал алгоритм сжатия LZ Prediction (LZP) из протокола PPP, изменив хеш-функцию эмпирическим путём. Prediction-байты сохраняются отдельно от данных, в base64-переменную, которая еще дополнительно обрабатывается существующим RLE-сжатием.
Приличную часть времени потратил на поддержку Internet Explorer 8 и Firefox 52: последним сёрфят как минимум 400 пользователей сервиса (кто-то «чистым» FF, кто-то K-Meleon/PaleMoon/SeaMonkey).
Визуально скорость не пострадала, но детально не измерял.
Сильно это, увы, не помогло. Файл опять едва вписывается в лимиты (но хотя бы обновляется).
1007799 proxy.pac
Принимаются другие идеи. Можно сконцентрироваться на исключении мусорных доменов.
Раздавать два PAC-скрипта: с ограничением в 1МБ и без этого ограничения.
Здравствуйте. Со вчерашнего дня софт pacproxy перестал работать с новым pac файлом. При этом браузер работает нормально. Могу я попросить ссылку на предыдущую версию рас файла, если таковая имеется? Также присоединяюсь к предложнению из предыдущего поста о распространении двух версий файлов. И извините если немного не в тему.
Можно так сделать. Взять все эти домены и пройтись по ним CURLом. Если там нет ответа, ошибка http или прочая ерунда, а так же заглушки паркингов или какие-то стандартные странички (надо изучать) , то в помойку.
Переделывать этот список, скажем, раз в неделю или 2. Лучше сделать так, что не сразу в помойку, а если 2 раза подряд в проверках он плохой, то надолго его в бан. А то мало ли временная проблема
Держать 2 последних плохих листа и в бан заносить только их пересечение.
Запускать по 50 тхредов, чтобы было быстрее.
Можно не париться на счет обиды кого-то. С точки зрения хостера это просто трафик определенного обьема, а для конечных сайтов это всего лишь 1 запрос. Нагрузки на CPU так же особо не усматривается.
Применять подмену user-agent на броузерный, иначе некоторые сайты могут неправильно себя повести.
Как вариант можно не курлами это делать из шелла, а на питоне что-то написать не очень сложное
Много так, увы, не вырезать. У меня есть список ресолвящихся доменов тут : https://raw.githubusercontent.com/bol-van/rulist/main/reestr_hostname_resolvable.txt
и в основном там есть какой-то сайт
Еще можно взять тот список и посмотреть на счет зеркал. Составить список regexp, чтобы резать многочисленные зеркала.
Пример : maxbet*, pinup* pin-up*, sex0*, solcasino*
проституток, наркоту и дипломы можно сразу убивать, возможно так же и казино
Это и сейчас реализовано с поиском по паттернам. У себя отбрасываю все вхождения с числом больше 1100 и результирующий файл получается ~800кб.
На счет ливнесс пробы в скрипте есть чекинг nxdomains. Он уменьшает размер на 400кб.
wc -l reestr_hostname_resolvable.txt
347090
grep casino reestr_hostname_resolvable.txt | wc -l
48700
grep bet reestr_hostname_resolvable.txt | wc -l
18121
grep prostitut reestr_hostname_resolvable.txt | wc -l
4486
grep diplom reestr_hostname_resolvable.txt | wc -l
3904
grep spravk reestr_hostname_resolvable.txt | wc -l
963
grep pinup reestr_hostname_resolvable.txt | wc -l
3441
grep pin-up reestr_hostname_resolvable.txt | wc -l
2264
Это уже около 25%
Это уже всё используется
https://bitbucket.org/anticensority/antizapret-pac-generator-light/src/master/config/exclude-regexp-dist.awk
Может подойти к проблеме с другой стороны - составить частотную характеристику запрашиваемых на стороне прокси доменов? И не включать в pac домены с популярностью менее определенного порога. Технические способы помогут только отсрочить проблему, но не решить ее кардинально, ибо данный список будет только увеличиваться. Я сильно сомневаюсь, что оставшиеся после фильтрации какие-нибудь *azino также востребованы, как и топовые новостные ресурсы в известной зоне. Так зачем тащить этот мертвый груз? А порог можно сделать плавающим, на основе собираемой статистики, чтобы укладываться в лимиты. Если конечно ведется такая статистика.
а дайте пожалуйста референсный исходник, не обязательно ркновский. давайте сделаем референсный файл на 10000 строк и будем смотреть на его примере что лучше сжимает. я сделал для себя lzw компрессию и минификацию. https://p.thenewone.lol:8443/proxy.pac тут на одних переносах строки можно не слабо сэкономить. еще можно миллиард азино превратить в один *.азино
Референс есть в репозитории.
ну нет, угадывать репо и файл в нем такое. как говорится, какое тз такое и хз
Что конкретно непонятно? Все ссылки есть в первом сообщении. В указанном бранче не выполняется обновление листа, и списки заморожены на дату коммита бранча, на них и тестируйте.
вот именно что списки, их поди еще там найди. а нужно один референсный исходный файл. типа “вот вам файл, задача сделать из него pac минимального размера без потери данных”.
Исходный файл списка, чтобы сделать другой PAC-файл с нуля?
Списки вот и вот, но эта другая задача, не по теме.
понял, вы не ищите способы минификации рас, вам нужно чтоб именно ваш файл оптимизировали.
Можно ли проверять User-Agent браузера? К примеру, пользователям IE и старых браузеров возвращать усечённый по объёму файл с наиболее популярными сайтами, а пользователям современных браузеров - полный?
Ещё вариант - некоторые зоны вынести сразу на прокси, к примеру, .com.ua и .co.il (новостные порталы Украины и Израиля), т.к. в этих зонах такое чувство, что гораздо больше заблоченных сайтов, чем не заблоченных.
Ограничение на размер файла есть только в Chrome и браузерах, основанных на нём. Выходит наоборот.
небольшую правку примете ?
https://bitbucket.org/anticensority/antizapret-pac-generator-light/pull-requests/1
Мы у себя не один год пользовались файлом https://antizapret.prostovpn.org/proxy.pac, заменяя в нем прокси-сервер на свой. Но antizapret.prostovpn.org заблокировали, поэтому прямой доступ стал невозможен. А через VPN предсказуемо получается “Your geoip is not RU, contact antizapret@prostovpn.org if you believe this is an error. THE SERVICE WORKS ONLY IN RUSSIA! Do not forget to include your IP address in the message.”
Ладно, решили делать proxy.pac сами, скачали/запустили Bitbucket. Но вот только результат 1.5Mb - нерабочий.
Поиском по темам нашелся GitHub - onminonA/proxy.pac: RU-PAC file anti-censorship in Russian Federation . Видимо пока будем использовать его, но мне кажется стоит сделать держать репозиторий antizapret-pac-generator-light в таком состоянии, чтобы им можно было практически пользоваться. Плюс сделать “официальный” аналог GitHub - onminonA/proxy.pac: RU-PAC file anti-censorship in Russian Federation, для локального использования.
Что же касается исходной проблемы, мне кажется надо активнее пользоваться списками исключений. Например отдельным скриптом составлять списки того, чего нет в whois, коммитить исключения в репозиторий (чтобы скрипт обновления не тормозил). Да и зеркала всяких казино в какой-то момент можно будет начать исключать.
Репозиторий находится именно в таком состоянии, в плане генерации PAC-файла он в точности соответствует версии на сервере. Отлаживайте.
Дело оказалось в RESOLVE_NXDOMAIN=“yes” (в репозитарии “no”).
И раз залез сюда, в topsequences.py имеет смысл обрабатывать последовательности длинее 4-х символов. Если обрабатывать 6 символов, используя или существующий символ из алфавита или почему-то неиспользуемый ‘_’, получается 989798 байт против исходных 1011183. Если использовать половину алфавита для 6, половину для 5 получится еще чуть короче. Но 2% это все равно конечно гомеопатия, РКН ничего не мешает за день столько добавить. Так что увы, боюсь без более активного использования исключений никуда.
diff -u topsequences.py.ok topsequences.py
…
+wordreplace_6 = [“_” + x for x in wordreplace]
…
for patternlen in (6,):
for round, _ in enumerate(wordreplace_6):
…
-wordreplace = wordreplace_big + wordreplace
+wordreplace = wordreplace_6 + wordreplace_big + wordreplace
@ValdikSS вариант с вычищенным списком РКН рассматривается? Есть сам список и наработки по методологии очищения списка (тесты, проверки)
Если есть дополнения и улучшения — добавляйте, конечно.
Файл опять близится к переполнению.
Тяжело…
Я не программист. Предлагаю взять список заблокированных доменов, да и выкинуть оттуда половину. Если есть статистика, наверняка активно используется 1% из этого списка.
А если выкинуть всё, что не ресолвится, просрочено?
Как показала история с морзянкой, такого там предостаточно.
Уже неоднократно и нересолв выкидывали, и от зеркал чистили, и откровенные непотребства удаляли; по-моему разве что именно не выкидывали намеренно сайты, которыми “типа никто ни пользуеца”, но так действительно делать не желательно. Все равно это паллиатив. Нужны именно мозги программистов чтобы решать эти проблемы. Простым юзверям тут особо делать нечего.
Как на счёт упакованного trie или минимальных хешей для доменов с последующим Elias-Fano кодированием для идентифиаторов нод?
Я хочу отметить что Роскомнадзор будет существовать ещё какое-то время в любом случае. Если ориентироваться на заранее заданный запас прочности, он рано или поздно всё равно исчерпается. Как минимум ОЧЕНЬ старые браузеры стоит отбросить из уравнения. Задача по определению нерешаемая. Ещё год назад было сложно что-то новое придумать, сейчас тем более. А если и появится что-то новое, это даст год очередной, может два, от поддержки старых браузеров придётся всё равно отказываться, а у новых скорее всего и ограничения будут другие.
@ValdikSS подумайте, отказ от старых браузеров естественный процесс. Я предлагаю брать за новый ориентир флэш-хромиумы 87-й версии 2020 года - ими пользуются из-за любви к флэшплееру и там ещё была поддержка Windows xp. И то даже они уже очень многие сайты нормально не открывают. Тут же у вас по ссылке речь идёт ещё о 50-х версиях Файрфокса из 2017 года. Такой некрофилией занимаются очень, очень немногие. Ну и по файрфоксам логика примерно та же самая - вглубь сильно дальше чем на 5 лет не уходить. А вы пытаетесь держать живыми ещё интернет-эксплореры, не в обиду вам, это очень почётно, я ценю невероятно подобное уважение к своим пользователям.
Должно быть именно это резервным вариантом на случай если сжать всё же не получится, а не произвольно выкидывать домёны, как тут предлагали Шариковы.
нусуде по всему проблему решили если учитывать что последний раз обновлялось 15 августа
@ValdikSS, можно попробовать оформить как задачу с отфильтрованным от казино списком доменов для https://codegolf.stackexchange.com/
Там соответствующая аудитория найдёт лучшие варианты алгоритмов сжатия
Что вообще происходит с серверами Антизапрета? Читал что они заблокированы, но иногда они работают, а иногда нет. Можно каким-то образом защитить их от цензуры, к примеру использовать устойчивый протокол вроде shadowsocks или сделать обфускацию как с мостами в торе?
Как вариант, убирать повторяющиеся домены типа:
0-111.lordfilm0.biz
0-112.lordfilm0.biz
0-113.lordfilm0.biz
0-115.lordfilm0.biz
заменяя их на
lordfilm0.biz
такую замену сделал в своем скрипте AntiZapret-VPN/setup/root/antizapret/parse.sh at main · GubernievS/AntiZapret-VPN · GitHub
с обработкой исключений из nxdomain и заменой повторяющихся более 3х раз доменов на домены 2 уровня выходит 169 тысяч
в exclude-regexp-dist.awk можно добавить еще исключения:
(/login/) {next}
(/signin/) {next}
(/bank/) {next}
(/secure/) {next}
(/verify/) {next}
(/account/) {next}
(/billing/) {next}
(/password/) {next}
(/invoice/) {next}
(/casino/) {next}
(/bet/) {next}
(/poker/) {next}
(/blackjack/) {next}
(/roulette/) {next}
(/slots/) {next}
(/winbig/) {next}
(/jackpot/) {next}
(/1win/) {next}
(/admiralx/) {next}
(/escort/) {next}
(/striptiz/) {next}
(/massaj/) {next}
(/stavki/) {next}
(/vulkan/) {next}
(/sloty/) {next}
(/prostitutki/) {next}
(/intim/) {next}
(/kokain/) {next}
(/xanax/) {next}
(/xanaks/) {next}
(/anasha/) {next}
(/escort/) {next}
(/pytana/) {next}
(/prostitutka/) {next}
(/metadon/) {next}
(/mefedron/) {next}
(/krokodil/) {next}
(/amfetamin/) {next}
(/drug/) {next}
(/narcotic/) {next}
(/meth/) {next}
(/weed/) {next}
(/vzyatka/) {next}
(/bribe/) {next}
(/russianbrides/) {next}
(/gamble/) {next}
(/blacksprut/) {next}
(/ecstasy/) {next}
У меня до сих пор жив EEEPC 904 HD и на нём стоит Windows 7 и даже обновляется каждый месяц расширенными апдейтами. Похоронить ОС древнее 7 пора уже давно и везде.
Рассмотрите вариант использование списков скриптов-чистилок с re:filter
(отсортированный и причесанный от мусора zapret-info)
Как насчет формировать PAC-файл динамически под клиента?
Отдельный обучающий PAC-файл, в котором вместо перечня всех заблокированных только используемые/посещаемые клиентом ресурсы с разделением на DIRECT/PROXY.
Для всех пока не классифицированных ресурсов по умолчанию возвращает специальные обучающие PROXY.
Которые идентифицируют клиента и сохраняют для него списки для формирования его личного PAC-файла.
Подобный обучающий прокси может быть поднят самостоятельно.
Иной вариант это использование специального DNS-сервера и функции PAC-файла dnsResolve.
Скрипт добавляет нечто к исходному имени ресурса и пытается разрешить в IP-адрес.
Например для url c “ntc.party” добавляем несуществующий корневой домен “.antizapret” и полученное имя сервера “ntc.party.antizapret” пытаемся получить IP.
Если IP получили (или нет) можно сделать вывод надо или нет проксировать исходный URL.
А в зависимости от IP можно отправлять на разные прокси.
@ValdikSS Рассматривали сжатый DAWG (Directed Acyclic Word Graph)? Возможно подойдёт что-то такое
Да и base85 маловато для cp1252. Если оно все печатаемые символы хавает, можно намного больше взять
@ValdikSS
Попробовал на своем домене и vps поднять dnsmasq и поиграться с идеей разрешения адреса прокси.
Прикольно, оно работает.
Практически даже не требуется в dns-сервера (клиента) прописывать этот специальный dns, через глобальную dns прекрасно работает.
Так же можно не только домены но и отдельные заблокированные страницы и ip-адреса/подсети через dns узнавать онлайн - требуется проксирование или нет.
И получать свежие адреса прокси-серверов, без изменения PAC-скрипта.
Фактически некая маскировка под dns-трафик получается, двустороннее общение (из PAC-файла) со своими серверами, посредством функции dnsResolve.
Осталось продумать кодирование запросов/ответов и реализовать заполнение conf для dnsmasq.
В этот же список можно добавить:
(/caino/) {next}
(/cassino/) {next}
(/cazzino/) {next}
(/cazinno/) {next}
(/casiino/) {next}
(/casin0/) {next}
(/casi1no/) {next}
(/cas1no/) {next}
(/kacino/) {next}
(/kazzino/) {next}
(/cocaine/) {next}
(/businessinvest/) {next}
(/syka/) {next}
(/slot/) {next}
(/seeds/) {next}
(/fontan/) {next}
Спасибо, дополнил свой список
Вариант с PAC файлом в принципе не работает. По ссылке https://p.thenewone.lol:8443/proxy.pac открывается заглушка “This content has been blocked. Please contact team@pinata.cloud for more information - ERR_ID:00023”
Ссылка была заблочена но при этом сам pac-файл работал (у тех у кого это две отдельные сущности). Сейчас и он сам не работает. Нужно победить эту проблему, а она сложная.
PAC-файл уменьшен в размере путём проверки HTTP/HTTPS-работоспособности доменов, должен снова работать в Chrome-подобных браузерах при добавлении в настройки ОС.
А где взять рабочую ссылку на PAC-файл?
@ValdikSS @ilyaigpetrov Антицензорити придерживается лимитов на размер в 10 мегабайт и я используя его в ZeroOmega не замечаю каких-либо тяжёлых негативных эффектов. Можно спросить, почему лимит в 1 мегабайт так важен для Антизапрета и кого именно затронет практически НЕИЗБЕЖНЫЙ отход от лимита в 1 мегабайт? Допустим файл весит 3 мегабайта вместо 900 килобайт, какие негативные эффекты сразу ощутят конечные пользователи, в каких сценариях?
Все браузеры, основанные на Chromium (Chrome, Edge, Opera, Vivaldi, Brave), а также программы на CEF (Electron) не работают с PAC-файлами больше 1 МБ.
И ладно бы если просто не работали, но если файл по PAC-ссылке больше 1 МБ, они воспринимают это как временную проблему и не кешируют ответ, постоянно отправляя всё новые и новые запросы на скачивание файла, устраивая DDoS.
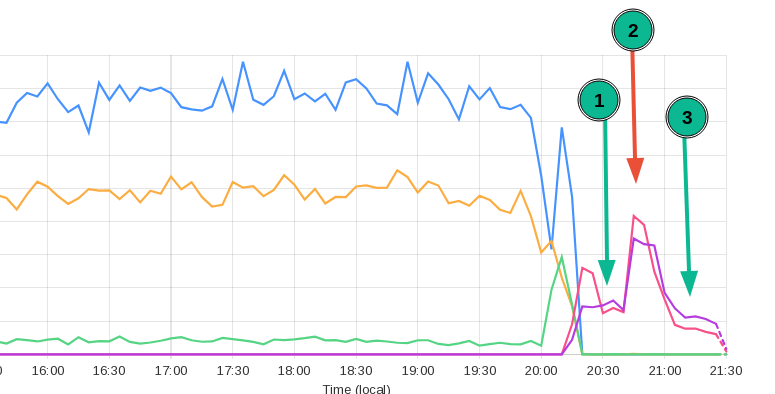
PAC-файл АнтиЗапрета >1МБ, вероятно, привёл к блокировке российских IP-адресов на IPFS-гейтвее pinata, а после переключения — к огромному количеству запросов на IPFS-гейтвей ipfs.io, что они были вынуждены сделать rate limit на 5 запросов в час с одного адреса — запросы PAC-файла просто съедали всю их пропускную способность.
I’m looking at our bandwidth utilization and
/ipfs/CID/proxy-ssl.jsand/ipfs/CID/proxy-nossl.jsare in TOP 3 of requested paths.
ok, seems that the fix was you ensuring size below 1MiB - it significantly cut down (1) bandwidth
it spiked again when I disabled rate-limits (2) and then got back down again (3) once I re-enabled them.
rate-limiting does not seem to have the same runaway effect as 1MiB thing – I think modern browsers/windows do support Retry-After, or have some sort of smart backoff when != 200 or 429 is returned.
PAC-файлы больше 1 МБ поддерживаются только в расширениях.
Чем меньше доменов в файле, тем быстрее он обрабатывается. Каждый запрос проиходит через PAC-функцию, поэтому чем быстрее она работает, тем меньше замедляются сетевые функции браузера.
В Реестре куча мусорных доменов/зеркал, которые технически работают, но никому не нужны.
Проблема устранена, по крайней мере на время. Если у кого есть более продуктивные идеи — пишите личным сообщением.